A Twitter 10 évvel ezelőtti nyilvános bevezetése óta közösségi hálózaton, a barátok körében, az azonnali üzenetküldő szolgáltatásként okostelefon-felhasználók számára, valamint promóciós eszközként szolgál a vállalatok és a politikusok számára.
De felbecsülhetetlen adatforrás volt azoknak a kutatóknak és tudósoknak is - mint én -, akik meg akarják vizsgálni, hogy az emberek hogyan érzik magukat és hogyan működnek az összetett társadalmi rendszerekben.
A tweetek elemzésével kontrollált laboratóriumi kísérleteken kívül megfigyelhetjük és adatokat gyűjthetjük emberek millióinak „a vadonban” történő társadalmi interakcióiról.
Ez lehetővé tette számunkra, hogy dolgozzunk ki eszközöket a nagy populációk kollektív érzelmei, Találd meg legvidámabb helyek az Egyesült Államokban és még sok más.
Tehát hogyan lett a Twitter ilyen egyedülálló forrás a számítástechnikai társadalomtudósok számára? És mit engedett felfedezni?

A Twitter legnagyobb ajándéka a kutatóknak
15. július 2006-én a Twittr (amint akkor ismert volt) nyilvánosan indított „mobil szolgáltatásként, amely segíti a baráti társaságokat véletlenszerű gondolatok visszaverésében SMS-ben”. Ingyenes 140 karakteres csoportos szövegek küldésének képessége sok korai alkalmazót (beleértve engem is) arra késztette a platform használatát.
Idővel a felhasználók száma felrobbant: a 20-es 2009 millióról a 200-es 2012 millióra és a mai 310 millióra. A felhasználók nem közvetlenül kommunikálnak a barátaikkal, hanem a felhasználók egyszerűen elmondják követőiknek, hogy mit éreznek, pozitívan vagy negatívan reagálnak a hírekre, vagy tréfálkoznak.
A kutatók számára a Twitter legnagyobb ajándéka nagy mennyiségű nyílt adat rendelkezésre bocsátása volt. A Twitter volt az első nagy közösségi hálózatok között, amelyek adatmintákat szolgáltattak úgynevezett Application Programming Interfaces (API) révén, amelyek lehetővé teszik a kutatók számára, hogy lekérdezzék a Twitteren bizonyos típusú tweeteket (pl. Bizonyos szavakat tartalmazó tweeteket), valamint információkat a felhasználókról. .
Ez a kutatási projektek robbanásához vezetett, felhasználva ezeket az adatokat. Ma a Google Scholar „Twitter” keresése hatmillió találatot eredményez, szemben a „Facebook” ötmillióval. A különbség különösen szembetűnő, tekintve, hogy a Facebook nagyjából ötször annyi felhasználó, mint a Twitter (és két évvel idősebb).
A Twitter nagylelkű adatpolitikája kétségtelenül kiváló ingyenes reklámhoz vezetett a vállalat számára, mivel érdekes tudományos tanulmányokat kapott a mainstream média.
A boldogság és az egészség tanulmányozása
Mivel a hagyományos népszámlálási adatok lassúak és költségesek gyűjteni, a nyílt adatcsatornák, mint például a Twitter, valós idejű ablakot adhatnak a nagy népesség változásainak megtekintésére.
A Vermonti Egyetem Számítási történetlabor 2006-ban alakult, és az alkalmazott matematika, a szociológia és a fizika problémáit tanulmányozza. 2008 óta a Story Lab több millió tweetet gyűjtött a Twitter „Gardenhose” hírcsatornáján keresztül, amely egy API, amely valós idejű véletlenszerű mintát közvetít az összes nyilvános tweet 10% -áról.
Három évet töltöttem a Computational Story Lab-ban, és szerencsés voltam, hogy számos érdekes tanulmány részese lehettem ezen adatok felhasználásával. Például kifejlesztettük a hedométer amely valós időben méri a Twittersphere boldogságát. Az okostelefonokról küldött geolokált tweetekre összpontosítva sikerült térkép az Egyesült Államok legboldogabb helyei. Talán nem meglepő módon találtuk Hawaii a legboldogabb állam, a bortermelő Napa pedig a legboldogabb város A 2013.
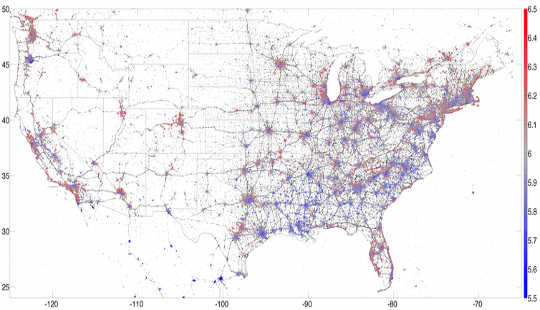 13-ból származó 2013 millió geolokált amerikai tweet térkép, amelyet boldogság színez, piros a boldogságot, a kék pedig a szomorúságot jelzi. PLoS ONE, Szerző megadta.Ezeknek a tanulmányoknak mélyebb alkalmazásuk volt: A Twitter szóhasználat és a demográfiai adatok korrelálása segített megérteni a mögöttes társadalmi-gazdasági mintákat a városokban. Összekapcsolhatjuk például a szóhasználatot olyan egészségügyi tényezőkkel, mint az elhízás, ezért felépítettük a lexikokaloriméter a közösségi média bejegyzések „kalóriatartalmának” mérésére. A magas kalóriatartalmú ételeket említő, egy adott régióból származó tweetek növelik az adott régió „kalóriatartalmát”, míg a testmozgást említő tweetek csökkentik a mutatóinkat. Megállapítottuk, hogy ez az egyszerű intézkedés korrelál az egészség és a jólét egyéb mutatóival. Más szavakkal, a tweetek képesek voltak pillanatképet adni egy adott pillanatban a város vagy régió általános egészségi állapotáról.
13-ból származó 2013 millió geolokált amerikai tweet térkép, amelyet boldogság színez, piros a boldogságot, a kék pedig a szomorúságot jelzi. PLoS ONE, Szerző megadta.Ezeknek a tanulmányoknak mélyebb alkalmazásuk volt: A Twitter szóhasználat és a demográfiai adatok korrelálása segített megérteni a mögöttes társadalmi-gazdasági mintákat a városokban. Összekapcsolhatjuk például a szóhasználatot olyan egészségügyi tényezőkkel, mint az elhízás, ezért felépítettük a lexikokaloriméter a közösségi média bejegyzések „kalóriatartalmának” mérésére. A magas kalóriatartalmú ételeket említő, egy adott régióból származó tweetek növelik az adott régió „kalóriatartalmát”, míg a testmozgást említő tweetek csökkentik a mutatóinkat. Megállapítottuk, hogy ez az egyszerű intézkedés korrelál az egészség és a jólét egyéb mutatóival. Más szavakkal, a tweetek képesek voltak pillanatképet adni egy adott pillanatban a város vagy régió általános egészségi állapotáról.
A Twitter-adatok gazdagságát felhasználva mi is képesek voltunk rá soha nem látott részletességgel látja az emberek napi mozgási szokásait. Az emberi mobilitási minták megértése viszont képes átalakítani a betegség modellezését, megnyitva ezzel az új területet digitális epidemiológia.
Más tanulmányok során megvizsgáltuk, hogy az utazók nagyobb boldogságot fejeznek-e ki a Twitteren, mint azok, akik otthon maradnak (válasz: igen), és ha igen a boldog egyének hajlamosak összetartani egy közösségi hálóban (megint megteszik). Valóban, úgy tűnik, hogy a pozitivitás magában a nyelvbe süllyed, abban az értelemben, hogy több pozitív szavunk van, mint negatív. Ez nem csak a Twitteren volt, hanem különféle médiumokban (pl. Könyvek, filmek és újságok) és nyelveken.
Ezek a tanulmányok - és több ezer hasonló ember a világ minden tájáról - csak a Twitter jóvoltából voltak lehetségesek.
A következő 10 év
Mit várhatunk tehát a Twitterről az elkövetkező 10 évben?
A legizgalmasabb munka egy része jelenleg a közösségi média adatainak matematikai modellekkel való összekapcsolása a népességszintű jelenségek, például a betegség kitörésének előrejelzése érdekében. A kutatók már némi sikert arattak a betegségmodellek Twitter-adatokkal való kiegészítésében az influenza, nevezetesen a FluOutlook platformot az Északkeleti Egyetem és a Tudományos Csere Intézete fejlesztette ki.
Ennek ellenére számos kihívás marad. A közösségi média adatai nagyon alacsony „jel-zaj arányban” szenvednek. Más szavakkal, az adott tanulmány szempontjából releváns tweeteket gyakran elnyomja a lényegtelen „zaj”.
Ezért folyamatosan tudatában kell lennünk annak, amit szinkronizáltunknagy adat hubris”, Amikor új módszereket fejlesztenek ki, és ne legyenek túl magabiztosak az eredményeinkben. Ehhez kapcsolódnia kell arra, hogy értelmezhető „üvegdobozos” előrejelzéseket hozzon létre ezekből az adatokból (szemben a „fekete dobozos” jóslatokkal, amelyekben az algoritmus rejtve van vagy nem egyértelmű).
A közösségi média adatait gyakran (meglehetősen) bírálják, hogy kicsi, nem reprezentatív minta a szélesebb népesség körében. Az egyik legnagyobb kihívás a kutatók számára az, hogy kitaláljuk, hogyan lehet az ilyen torz adatokat statisztikai modellekben figyelembe venni. Míg évente többen használják a közösségi médiát, folytatnunk kell az ezen adatok torzításainak megértését. Például az adatok továbbra is általában felülreprezentálják a fiatalabb személyeket az idősebb népesség rovására.
A kutatók csak a jobb elfogultság-korrekciós módszerek kidolgozása után képesek magabiztos előrejelzéseket tenni a tweetekből.
A szerzőről
Lewis Mitchell, az alkalmazott matematika oktatója, University of Adelaide
Ezt a cikket eredetileg közzétették A beszélgetés. Olvassa el a eredeti cikk.
Kapcsolódó könyvek
at InnerSelf Market és Amazon